

适合进阶 Python。本书类似 Python Cookbook 或者 Fluent Python,但是更偏重工程实践,不止于概念 Tricks 本身,更在乎如何用这些技术的最佳实践构建出可靠、优雅和 Pythonic 的工程。由于是新书,里面的概念还是比较新,type hints与mypy的类型检查方案是有的,但是似乎没有对 PEP 585 进行修订。
—— 豆瓣网友@歧路花火 2022-05-20 18:18:42
第 1 章 变量和注释 #
在一段代码中,变量和注释是最接近自然语言的东西。因此好的变量名、简明扼要的注释,都可以显著提高代码的质量。
这一章主要是介绍了常用的变量命名的原则,介绍了编程写代码的注释的集中方式。
1. 变量的命名使用原则 #
1. 星号表达式 #
可以使用星号表达式(*variables)作为变量名,他便会贪婪地捕获多个值对象,并将捕获到的内容作为列表赋值给 variables 。
例如:
>>> data = ['piglei', 'apple', 'orange', 'banana', 100]
>>> username, *fruits, score = data
>>> username
'piglei'
>>> fruits
['apple', 'orange', 'banana']
>>> score
100
有时候可以配合单下划线 _ 使用,通常可以在想要忽视某些变量时候使用,
例如:
# 忽略展开时的第二个变量
>>> author, _ = usernames
# 忽略第一个和最后一个变量之间的所有变量
>>> username, *_, score = data
2. 给变量注明类型 #
因为 Python 是动态类型语言,使用变量时不需要做任何的类型声明。但是为了代码的可读性,还是建议使用类型注解(Python3.5+版本)。
要使用类型注解,只需要在变量后添加类型,并用冒号隔开即可,比如 func(value: str) 表示函数的 value 参数为字符串类型.
3. 变量命名原则 #
变量起名要遵循 PEP8 原则。
尽量给变量起描述性强的名字,同时变量名尽量短。
其中有一类超短命名,使用一两个字母来命名,下面是一些约定俗成的变量名字:
- 数组索引三剑客 i、j、k
- 某个整数 n
- 某个字符串 s
- 某个异常 e
- 文件对象 fp
同一段代码中尽量避免多个相似的变量名,比如同时使用 users,users1,uesrs2 这种序列。
4. 保持变量的一致性 #
使用变量时,需要保证他在两方面的一致性,名字一致性和类型一致性。
名字一致性是指在同一个项目(或者模块、函数)中,对一类事物的称呼不要变来变去。
类型一致性则是指不要把同一个变量重复指向不同类型的值。举例:
def foo():
# users 本身是一个 Dict
users = {'data': ['piglei', 'raymond']}
...
# users 这个名字真不错!尝试复用它,把它变成 List 类型
users = []
...
在 foo() 函数的作用域内,users 变量被使用了两次:第一次指向字典,第二次则变成了列表。
2. 注释的注意事项 #
1. 接口注释 #
在编写接口文档时,我们应该站在函数设计者的角度,着重描述函数的功能、参数说明等。
而函数自身的实现细节——比如调用了哪个第三方模块、为啥有性能问题等,都不用放在接口文档里。
对于 resize_image() 函数来说,文档里提供以下内容就足够了:
def resize_image(image, size):
"""将图片缩放为指定尺寸,并返回新的图片。
注意:当文件超过 5MB 时,请使用 resize_big_image()
:param image: 图片文件对象
:param size: 包含宽高的元组:(width, height)
:return: 新图片对象
"""
2. 空行也是一种 “注释” #
在写代码时,我们可以适当的在代码中插入空行,把代码按不同的逻辑块分隔开来,这样能有效提高代码可读性。
3. 先写注释,后写代码 #
主要是为了避免写完代码之后,对待注释草草应付了事。
第 2 章 数值与字符串 #
这一章主要是介绍了 Python 中数值的基础知识和字符串的使用技巧。
1. 数值的基础知识 #
1. decimal 模块 #
Python 的浮点数有精度问题,可以使用 decimal.Decimal 对象来代替普通浮点数,做精确计算。例如:
>>> from decimal import Decimal
# 注意:这里的'0.1'和'0.2' 必须是字符串
>>> Decimal('0.1') + Decimal('0.2')
Decimal('0.3')
2. 字符串的使用 #
1. 字符串的内置方法 #
记录了字符串中常用和不常用的方法:
reversed,反转字符串
>>> s = 'Hello, world!'
>>> ''.join(reversed(s))
'!dlrow ,olleH'
reversed 会返回一个可迭代对象,通过字符串的 .join 方法可以将它转换为字符串。
.startswith(),检查字符串是否以指定的前缀开始。它返回布尔值 True 或 False。
text = "Hello, world!"
print(text.startswith("Hello")) # 输出: True
print(text.startswith("world")) # 输出: False
.partation(),用于在第一次出现指定 分隔符 的位置将字符串分成三部分:
分隔符前的部分、分隔符本身、和分隔符后的部分。它返回一个包含这三部分的元组。
text = "Hello, world!"
result = text.partition(", ")
print(result) # 输出: ('Hello', ', ', 'world!')
和 .split() 的区别,.partition() 返回了一个三元素的元组,而 .split() 返回了一个列表,并且列表中不包含分隔符。
.translate(table),按规则一次性替换多个字符,使用它比调用多次replace方法更快也更简单。
>>> s = '明明是中文,却使用了英文标点.'
# 创建替换规则表:',' -> ',', '.' -> '。'
>>> table = s.maketrans(',.', ',。')
>>> s.translate(table)
'明明是中文,却使用了英文标点。'
.rsplit(),就是split()的镜像“逆序”方法。
#从右往左切割,None表示以所有的空白字符串切割
>>> log_line.rsplit(None, maxsplit=1)
['"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"', '47632']
2. 字符串格式化 #
推荐使用 f-string 字符串格式化。
username, score = 'piglei', 100
# f-string,最短最直观
print(f'Welcome {username}, your score is {score:d}')
# 输出:
# Welcome piglei, your score is 100
3. Jinja2 模板处理字符串 #
Jinja2 是一个用于 Python 的模板引擎,可以用来生成动态内容。它通过在模板中嵌入变量和控制结构(如循环和条件)来处理字符串。
from jinja2 import Template
_MOVIES_TMPL = '''\
Welcome, {{username}}.
{%for name, rating in movies %}
* {{ name }}, Rating: {{ rating|default("[NOT RATED]", True) }}
{%- endfor %}
这个字符串 _MOVIES_TMPL 是一个 Jinja2 模板,包含以下内容:
- {{username}} 是一个占位符,将被传入的 username 变量替换。
- {%for name, rating in movies %}…{% endfor %} 是一个循环结构,用于遍历传入的 movies 列表。
- {{ name }} 是每部电影的名字,占位符将被电影的名字替换。
- {{ rating|default("[NOT RATED]", True) }} 是电影的评分,占位符将被电影的评分替换。如果评分不存在,则使用默认值 [NOT RATED]。
3. timeit 模块测试性能 #
Python有一个内置模块timeit,利用它,我们可以非常方便地测试代码的执行效率。
首先,定义需要测试的两个函数:
#定义一个长度为 100的词汇列表
WORDS = ['Hello', 'string', 'performance', 'test'] * 25
def str_cat():
"""使用字符串拼接"""
s = ''
for word in WORDS:
s += word
return s
def str_join():
"""使用列表配合 join 产生字符串"""
l = []
for word in WORDS:
l.append(word)
return ''.join(l)
然后,导入timeit模块,定义性能测试:
import timeit
# 默认执行 100 万次
cat_spent = timeit.timeit(setup='from __main__import str_cat', stmt='str_cat()')
print("cat_spent:", cat_spent)
join_spent = timeit.timeit(setup='from __main__import str_join', stmt='str_join()')
print("join_spent", join_spent)
# 输出
# cat_spent: 7.844882188
# join_spent 7.310863505
第 3 章 容器类型 #
讲解了四种容器类型,列表,元组,字典,集合。同时介绍了对象的可变性、可哈希性等概念。
1. 列表 #
这里主要记录列表的性能陷阱
1. 插入数据 #
如果要在头部插入数据,使用 .insert() 平均时间复杂度是 O(n)(尾部插入数据使用 .append() 平均复杂度是 O(1))。
如果需要往列表头部插入数据,使用 collections.deque 类型来替代列表(代码如下)。因为 deque 底层使用了双端队列,无论在头部还是尾部追加成员,时间复杂度都是 O(1)。
from collections import deque
def deque_append():
"""不断往尾部追加"""
l = deque()
for i in range(5000):
l.append(i)
def deque_appendleft():
"""不断往头部插入"""
l = deque()
for i in range(5000):
l.appendleft(i)
# timeit 性能测试代码已省略
# deque_append: 3.739269677
# deque_appendleft 3.7188512409999994
2. 判断成员是否存在 #
要判断某个容器是否包含特定成员,用集合比用列表更合适。
完成这种操作需要的时间复杂度是O(1)。
如果代码需要进行 in 判断,可以考虑把目标容器转换成集合类型,作为查找时的索引使用:
#注意:这里的示例列表很短,所以转不转集合对性能的影响可能微乎其微
# 在实际编码时,列表越长、执行的判断次数越多,转成集合的收益就越高
VALID_NAMES = ["piglei", "raymond", "bojack", "caroline"]
# 转换为集合类型专门用于成员判断
VALID_NAMES_SET = set(VALID_NAMES)
def validate_name(name):
if name not in VALID_NAMES_SET:
raise ValueError(f"{name} is not a valid name!")
这样的话一次转换成集合 O(n)之后,后面查找都可以在 O(1)内。
2. 元组 #
1. 存放结构化数据 #
和列表不同,在同一个元组里可以出现不同类型的值,因此元组经常用来存放结构化数据。
>>> user_info = ('piglei', 'MALE', 30, True)
>>> user_info[2]
30
2. 具名数组 #
具名元组(namedtuple)。具名元组在保留普通元组功能的基础上,允许为元组的每个成员命名,这样你便能通过名称而不止是数字索引访问成员。(结构化数据)
用到 namedtuple() 函数创建具名数组:
from collections import namedtuple
Rectangle = namedtuple('Rectangle', 'width, height')
rect = Rectangle(100, 20)
rect = Rectangle(width=100, height=20)
print(rect[0])
# 100
print(rect.width)
# 100
【推荐】在Python 3.6版本以后,除了使用 namedtuple() 函数以外,你还可以用 typing.NamedTuple 和类型注解语法来定义具名元组类型。
另外对于这种未来可能会变动的多返回值函数来说,如果一开始就使用 NamedTuple 类型对返回结果进行建模,后面改动会变得简单许多:
class Rectangle(NamedTuple):
width: int
height: int
rect = Rectangle(100, 20)
3. 字典 #
1. 访问不存在的 Key #
当用不存在的键访问字典内容时,程序会抛出 KeyError 异常。
try:
rating = movie['rating']
except KeyError:
rating = 0
2. 快速合并字典 #
在不改变原字典内容的前提下,采用双星号 ** 运算符来做解包操作。在字典中使用 **dict_obj 表达式,可以动态解包 dict_obj 字典的所有内容,并与当前字典合并:
解包过程会默认进行 浅拷贝操作。
>>> d1 = {'name': 'apple'}
>>> d2 = {'price': 10}
# d1、d2 原始值不会受影响
>>> {**d1, **d2}
{'name': 'apple', 'price': 10}
4. 集合 #
集合只能存放 可哈希的对象。
5. 对象的可变性 #
Python里的内置数据类型,大致上可分为可变与不可变两种。
- 可变(mutable):列表、字典、集合。
- 不可变(immutable):整数、浮点数、字符串、字节串、元组。
一个最常见的场景“函数调用”:
在对字符串进行 += 操作时,因为字符串是不可变类型,所以程序会生成一个新对象(值):‘foo suffix’,并让 in_func_obj 变量指向这个新对象;旧值(原始变量orig_obj指向的对象)则不受任何影响。
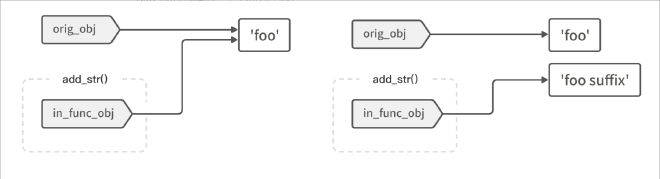
如果对象是可变的(比如列表),+= 操作就会直接原地修改 in_func_obj 变量所指向的值,而它同时也是原始变量 orig_obj 所指向的内容;待修改完成后,两个变量所指向的值(同一个)肯定就都受到了影响。
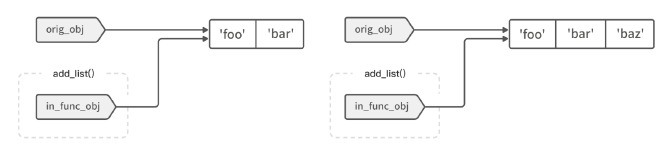
6. 深拷贝与浅拷贝 #
假如我们想让两个变量(可变的)的修改操作互不影响,就需要拷贝变量所指向的可变对象,做到让不同变量指向不同对象。
按拷贝的深度,常用的拷贝操作可分为两种:浅拷贝与深拷贝。
1. 浅拷贝 #
- 使用copy模块下的
copy()方法
>>> import copy
>>> nums_copy = copy.copy(nums)
>>> nums[2] = 30
# 修改不再相互影响
>>> nums, nums_copy
([1, 2, 30, 4], [1, 2, 3, 4])
- 使用各容器类型的内置构造函数
>>> d2 = dict(d.items())
>>> nums_copy = list(nums)
- 进行全切片
#nums_copy会变成 nums的浅拷贝
>>> nums_copy = nums[:]
- 有些类型自身就提供了浅拷贝方法
#列表有 copy方法
>>> num = [1, 2, 3, 4]
>>> nums.copy()
[1, 2, 3, 4]
# 字典也有 copy 方法
>>> d = {'foo': 'bar'}
>>> d.copy()
{'foo': 'bar'}
2. 深拷贝 #
但对于一些层层嵌套的复杂数据来说,浅拷贝仍然无法解决嵌套对象被修改的问题。
可以用 copy.deepcopy() 函数来进行深拷贝操作
>>> items = [1, ['foo', 'bar'], 2, 3]
>>> items_deep = copy.deepcopy(items)
7. 对象的可哈希性 #
计算哈希值的过程,是通过调用内置函数hash(obj)完成的。如果对象是可哈希的,hash函数会返回一个整型结果,否则将会报 TypeError 错误。
某种类型是否可哈希遵循下面的规则:
- 所有的不可变内置类型,都是可哈希的,比如str、int、tuple、frozenset等;
- 所有的可变内置类型,都是不可哈希的,比如dict、list,set等;
- 对于不可变容器类型(tuple, frozenset),仅当它的所有成员都不可变时,它自身才是可哈希的;
- 用户定义的类型默认都是可哈希的。谨记,只有可哈希的对象,才能放进集合或作为字典的键使用。
8. 生成器 #
生成器(generator)是Python里的一种特殊的数据类型。顾名思义,它是一个不断给调用方“生成”内容的类型。定义一个生成器,需要用到生成器函数与 yield 关键字。
def generate_even(max_number):
"""一个简单生成器,返回 0 到 max_number 之间的所有偶数"""
for i in range(0, max_number):
if i % 2 == 0:
yield i
for i in generate_even(10):
print(i)
yield 和 return 的最大不同之处在于,return 的返回是一次性的,使用它会直接中断整个函数执行,而 yield 可以逐步给调用方生成结果:
(其实可以把生成器返回的值想象成一个可以迭代的 list,需要迭代得出。)
>>> i = generate_even(10)
>>> next(i)
0
>>> next(i)
2
调用 next()可以逐步从生成器对象里拿到结果。
因为生成器是可迭代对象,所以你可以使用list()等函数方便地把它转换为各种其他容器类型:
>>> list(generate_even(10))
[0, 2, 4, 6, 8]
第 4 章 条件分支控制流 #
1. 分支惯用写法 #
1. 不要显式地和布尔值做比较 #
#不推荐的写法
# if user.is_active_member() == True:
# 推荐写法
if user.is_active_member():
2. 省略零值判断 #
当我们需要在条件语句里做空值判断时,可以直接把代码简写成下面这样:
if not containers_count:
...
if fruits_list:
...
· 布尔值为假:None、0、False、[]、()、{}、set()、frozenset(),等等。
· 布尔值为真:非0的数值、True,非空的序列、元组、字典,用户定义的类和实例,等等。
3. 与None比较时使用is运算符* #
当你需要判断某个对象是否是 None、True、False时,使用 is ,其他情况下,请使用 ==。
2. 常用函数优化分支 #
1. 使用bisect优化范围类分支判断 #
当在每个 if/elif 语句后,都跟着一个分界点时,
bisect 是 Python 内置的二分算法模块,它有一个同名函数 bisect,可以用来在有序列表里做二分查找。
>>> import bisect
# 注意:用来做二分查找的容器必须是已经排好序的
>>> breakpoints = [10, 20, 30]
# bisect 函数会返回值在列表中的位置,0 代表相应的值位于第一个元素 10 之前
>>> bisect.bisect(breakpoints, 1)
0
# 3 代表相应的值位于第三个元素 30 之后
>>> bisect.bisect(breakpoints, 35)
3
2. all()/any() 函数 #
all() 和 any()。这两个函数接收一个可迭代对象作为参数,返回一个布尔值结果。顾名思义,这两个函数的行为如下。
- all(iterable):仅当iterable中所有成员的布尔值都为真时返回 True,否则返回 False。
- any(iterable):只要iterable中任何一个成员的布尔值为真就返回 True,否则返回 False。
def all_numbers_gt_10_2(numbers):
return bool(numbers) and all(n > 10 for n in numbers)
3. 其他技巧 #
1. 要竭尽所能地避免分支嵌套 #
用一个简单的技巧来优化——“提前返回”。
“提前返回”指的是:当你在编写分支时,首先找到那些会中断执行的条件,把它们移到函数的最前面,然后在分支里直接使用 return 或 raise 结束执行。
2. 德摩根定律 #
德摩根定律”告诉了我们这么一件事:
not A or not B等价于not (A and B)。
#如果用户没有登录或者用户没有使用Chrome,拒绝提供服务
if not user.has_logged_in or not user.is_from_chrome:
return "our service is only available for chrome logged in user"
# 等价于下面
if not (user.has_logged_in and user.is_from_chrome):
return "our service is only available for chrome logged in user"
3. and和or的运算优先级 #
and 运算符的优先级高于 or !
4. or运算符的陷阱 #
使用 a or b 来表示 “ a为空时用b代替” 的写法非常常见。
但是,因为or计算的是变量的布尔真假值,所以不光是None,0、[]、{}以及其他所有布尔值为假的东西,都会在or运算中被忽略:
#所有的0、空列表、空字符串等,都是布尔假值
>>> bool(None), bool(0), bool([]), bool({}), bool(''), bool(set())
(False, False, False, False, False, False)
所以在使用 a or b 时候,一定要注意变量的布尔值真假。
第 5 章 异常与错误处理 #
本章主要是作者对异常处理的经验和技巧。
1. 异常捕获的经验技巧 #
1. 优先使用异常捕获 #
Python社区明显偏爱基于异常捕获的EAFP(asier to ask for forgiveness than permission)风格。
EAFP编程风格更为简单直接,它总是直奔主流程而去,把意外情况都放在异常处理try/except块内消化掉。
所以,每当直觉驱使你写下if/else来进行错误分支判断时,请先把这份冲动放一边,考虑用try来捕获异常是不是更合适。
2. try/except结构 #
常见的 try/except 基础语法如下:
def safe_int(value):
"""尝试把输入转换为整数"""
try:
return int(value)
except TypeError:
# 当某类异常被抛出时,将会执行对应 except 下的语句
print(f'type error: {type(value)} is invalid')
except ValueError:
# 你可以在一个 try 语句块下写多个 except
print(f'value error: {value} is invalid')
finally:
# finally 里的语句,无论如何都会被执行,哪怕已经执行了return
print('function completed')
3. 把更精确的 except 语句放在前面 #
如果一个try代码块里包含多条 except,异常匹配会按照从上而下的顺序进行。
这时,假如你不小心把一个比较模糊的父类异常放在前面,就会导致在下面的 except 永远不会被触发。
所以,把更精确的异常放在前面。
Python 的内置异常类之间存在许多继承关系,具体可以看 Python3.info。
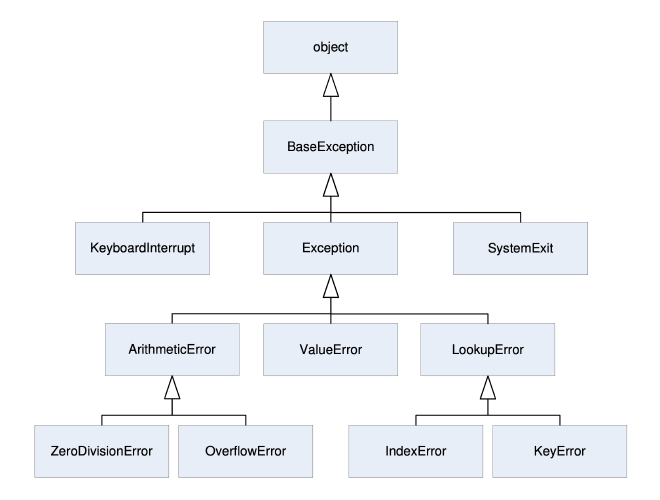
4. else 分支 #
如果使用 try 语句块里的 else 分支,代码可以变得更简单:
try:
sync_profile(user.profile, to_external=True)
except Exception as e:
print("Error while syncing user profile")
else:
send_notification(user, 'profile sync succeeded')
异常捕获语句里的 else 表示:仅当 try 语句块里没抛出任何异常时,才执行 else 分支下的内容,效果就像在 try 最后增加一个标记变量一样。
和finally语句不同,假如程序在执行try代码块时碰到了return或break等跳转语句,中断了本次异常捕获,那么即便代码没抛出任何异常,else分支内的逻辑也不会被执行。
5. raise 语句 #
在 Python 中,raise 语句用于引发一个异常,即中断程序的正常流程并生成一个错误。
raise Exception("这是一个一般性的错误")
# 输出
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# Exception: 这是一个一般性的错误
当我们想仅仅想记录下某个异常,然后把它重新抛出时,可以使用不带任何参数的 raise 语句。
def incr_by_key(d, key):
try:
d[key] += 1
except KeyError:
print(f'key {key} does not exists, re-raise the exception')
raise
当一个空 raise 语句出现在 except 块里时,它会原封不动地重新抛出当前异常及异常类型。
6. 可以自定义异常类 #
class CreateItemError(Exception):
"""创建 Item 失败"""
def create_item(name):
"""创建一个新的Item
:raises: 当无法创建时抛出 CreateItemError
"""
if len(name) > MAX_LENGTH_OF_NAME:
raise CreateItemError('name of item is too long')
if len(get_current_items()) > MAX_ITEMS_QUOTA:
raise CreateItemError('items is full')
return Item(name=name), ''
def create_from_input():
name = input()
try:
item = create_item(name)
except CreateItemError as e:
print(f'create item failed: {e}')
else:
print(f'item<{name}> created')
7. 不要手动做数据校验 #
在编写代码时,我们应当尽量避免手动校验任何数据。 因为数据校验任务独立性很强,所以应该引入合适的第三方校验模块(或者自己实现),让它们来处理这部分专业工作。
假如你在开发Web应用,数据校验工作通常来说比较容易。比如Django框架就有自己的表单验证模块,Flask也可以使用WTForms模块来进行数据校验。
第 6 章 循环与可迭代对象 #
本章主要是分享在 Python 里编写循环的一些经验和技巧,重点时迭代器与迭代器的使用。
1. iter() 与 next() 内置函数 #
iter() 会尝试返回一个迭代器对象
>>> iter([1, 2, 3])
<list_iterator object at 0x101a82d90>
>>> iter('foo')
<str_iterator object at 0x101a99ed0>
>>> iter(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
# 对不可迭代的类型执行iter()会抛出TypeError异常
什么是迭代器(iterator)?
顾名思义,这是一种帮助你迭代其他对象的对象。迭代器最鲜明的特征是:不断对它执行 next() 函数会返回下一次迭代结果。
>>> l = ['foo', 'bar']
# 首先通过 iter 函数拿到列表 l 的迭代器对象
>>> iter_l = iter(l)
>>> iter_l
<list_iterator object at 0x101a8c6d0>
# 然后对迭代器调用next() 不断获取列表的下一个值
>>> next(iter_l)
'foo'
>>> next(iter_l)
'bar'
当迭代器没有更多值可以返回时,便会抛出 StopIteration 异常。
2. 自定义迭代器 #
要自定义一个迭代器类型,关键在于实现下面这两个魔法方法:
·
__iter__:调用iter()时触发,迭代器对象总是返回自身。·
__next__:调用next()时触发,通过 return 来返回结果,没有更多内容就抛出 StopIteration 异常,会在迭代过程中多次触发。
3. 生成器是迭代器 #
生成器还是一种简化的迭代器实现, 使用它可以大大降低实现传统迭代器的编码成本。
基本不需要通过 __iter__ 和 __next__ 来实现迭代器,只要写上几个 yield 就行。
def range_7_gen(start, end):
"""生成器版本的Range7Iterator"""
num = start
while num < end:
if num != 0 and (num % 7 == 0 or '7' in str(num)):
yield num
num += 1
我们可以用 iter() 和 next() 函数来验证“生成器就是迭代器”这个事实:
>>> nums = range_7_gen(0, 20)
# 使用iter() 函数测试
>>> iter(nums)
<generator object range_7_gen at 0x10404b2e0>
>>> iter(nums) is nums
True
# 使用next() 不断获取下一个值
>>> next(nums)
7
>>> next(nums)
14
生成器(generator) 利用其简单的语法,大大降低了迭代器的使用门槛,是优化循环代码时最得力的帮手。
4. 修饰可迭代对象优化循环 #
这里主要讲的是一种循环代码的优化思路,通过修饰可迭代对象来优化循环。
通俗的来讲其实就是:迭代(迭代器)。可以类比与 enumerate 的做法。
“修饰可迭代对象”是指用生成器(或普通的迭代器)在循环外部包装原本的循环主体,完成一些原本必须在循环内部执行的工作——比如过滤特定成员、提供额外结果等,以此简化循环代码。
5. 读取大文件 #
调用 file.read(chunk_size) ,会马上读取从当前游标位置往后 chunk_size 大小的文件内容. 解决读取大文件的性能问题。
from functools import partial
def count_digits_v3(fname):
count = 0
block_size = 1024 * 8
with open(fname) as fp:
# 使用functools.partial 构造一个新的无须参数的函数
_read = partial(fp.read, block_size)
# 利用iter() 构造一个不断调用_read 的迭代器
for chunk in iter(_read, ''):
for s in chunk:
if s.isdigit():
count += 1
return count