
第 7 章 函数 #
分享一些在 Python 里编写函数的技巧。
1. 仅限关键字参数 #
当调用参数较多(超过3个)的函数时,使用关键字参数模式可以大大提高代码的可读性。
通过在参数列表中插入 * 符号,该符号后的所有参数都变成了“仅限关键字参数”(keyword-only argument)。调用的时候必须加入调用的参数名:
#注意参数列表中的* 符号
def query_users(limit, offset, *, min_followers_count, include_profile):
...
# 调用函数
>>> query_users(20, 0, 100, True)
# 执行后报错:
TypeError: query_users() takes 2 positional arguments but 4 were given
# 正确的调用方式
>>> query_users(20, 0, min_followers_count=100, include_profile=True)
2. 返回 None 值 #
一般在“搜索”、“查询”这两个场景会使用 None 值进行返回。
3. 给函数加上状态 —— 闭包 #
闭包是一种非常有用的工具,非常适合用来实现简单的有状态函数。
闭包是一种允许函数访问已执行完成的其他函数里的私有变量的技术,是为函数增加状态的另一种方式。
我感觉就是函数套函数,其实和下一章的装饰器有很大的联系。
正常情况下,当Python完成一次函数执行后,本次使用的局部变量都会在调用结束后被回收,无法继续访问。但是,如果你使用下面这种“函数套函数”的方式,在外层函数执行结束后,返回内嵌函数,后者就可以继续访问前者的局部变量,形成了一个“闭包”结构,
def counter():
value = 0
def _counter():
# nonlocal 用来标注变量来自上层作用域,如不标明,内层函数将无法直接修改外层函数变量
nonlocal value
value += 1
return value
return _counter
其实上面的更好的方法时用类(class)实现, 只需要用类中初始化状态 __init__ 实现就好。
抽象的概念 #
同一个函数代码应该处于同一抽象级别内。
详见书中 P196 - P203
第 8 章 装饰器 #
一些在 Python 中编写装饰器的技巧,以及几个用于编写装饰器的常见工具。
1. 装饰器基础 #
装饰器是一种通过包装目标函数来修改其行为的特殊高阶函数,绝大多数装饰器是利用函数的 闭包原理实现的。
1. 无参数装饰器 #
def timer(func):
"""装饰器:打印函数耗时"""
def decorated(*args, **kwargs):
st = time.perf_counter()
ret = func(*args, **kwargs)
print('time cost: {} seconds'.format(time.perf_counter() - st))
return ret
return decorated
在写装饰器时,我一般把 decorated 叫作 “包装函数”。
2. 有参数装饰器 #
def timer(print_args=False):
"""装饰器:打印函数耗时
:param print_args: 是否打印方法名和参数,默认为 False
"""
def decorator(func):
def wrapper(*args, **kwargs):
st = time.perf_counter()
ret = func(*args, **kwargs)
if print_args:
print(f'"{func.__name__}", args: {args}, kwargs: {kwargs}')
print('time cost: {} seconds'.format(time.perf_counter() - st))
return ret
return wrapper
return decorator
在应用有参数装饰器时,一共要做两次函数调用,所以装饰器总共得包含三层嵌套函数。
2. 使用 functools.wraps() 修饰包装函数。
#
在装饰器包装目标函数的过程中,常会出现一些副作用,其中一种是丢失函数元数据。
会出现下面的情况:
>>> random_sleep.__name__
'decorated'
>>> print(random_sleep.__doc__)
None
或者饰器给函数追加的属性找不到了。
要解决这个问题,我们需要在装饰器内包装函数时,保留原始函数的额外属性。
而 functools 模块下的 wraps() 函数正好可以完成这件事情。使用 wraps(),装饰器只需要做一点儿改动:
from functools import wraps
def timer(func):
@wraps(func)
def decorated(*args, **kwargs):
...
return decorated
添加 @wraps(wrapped) 来装饰 decorated 函数后,wraps() 首先会基于原函数 func 来更新包装函数 decorated 的名称、文档等内置属性,之后会将 func 的所有额外属性赋值到 decorated 上。
3. 用类来实现装饰器 #
判断对象是否能通过装饰器(@decorator)的形式使用只有一条判断标准,那就是 decorator 是不是一个可调用的对象。
自然函数是可调用的对象。
>>> class Foo:
... pass
...
>>> callable(Foo)
True
# 使用callable()内置函数可以判断某个对象是否可调用。
类(class)也可以是调用对象,前提是一个类中实现了 __call__ 魔法方法,那么他的实例也会变成调用对象。
>>> class Foo:
... def __call__(self, name):
... print(f'Hello, {name}')
...
>>> foo = Foo()
>>> callable(foo)
True
>>> foo('World')
Hello, World
1. 函数替换装饰器 #
这种技术最适合用来实现接收参数的装饰器。
class timer:
"""装饰器:打印函数耗时
:param print_args: 是否打印方法名和参数,默认为 False
"""
def __init__(self, print_args):
self.print_args = print_args
def __call__(self, func):
@wraps(func)
def decorated(*args, **kwargs):
st = time.perf_counter()
ret = func(*args, **kwargs)
if self.print_args:
print(f'"{func.__name__}", args: {args}, kwargs: {kwargs}')
print('time cost: {} seconds'.format(time.perf_counter() - st))
return ret
return decorated
(1)第一次调用:_deco = timer(print_args=True) 实际上是在初始化一个 timer 实例。
(2)第二次调用:func = _deco(func) 是在调用 timer 实例,触发 __call__ 方法。
2. “实例替换”装饰器 #
无参数装饰器 DelayedStart
class DelayedStart:
"""在执行被装饰函数前,等待 1 秒钟"""
def __init__(self, func):
update_wrapper(self, func) ➊
self.func = func
def __call__(self, *args, **kwargs): ➋
print(f'Wait for 1 second before starting...')
time.sleep(1)
return self.func(*args, **kwargs)
def eager_call(self, *args, **kwargs): ➌
"""跳过等待,立刻执行被装饰函数"""
print('Call without delay')
return self.func(*args, **kwargs)
- ❶ update_wrapper与前面的wraps一样,都是把被包装函数的元数据更新到包装者(在这里是DelayedStart实例)上。
- ❷ 通过实现
__call__方法,让 DelayedStart 的实例变得可调用,以此模拟函数的调用行为。 - ❸ 为装饰器类定义额外方法,提供更多样化的接口。
>>> @DelayedStart
... def hello():
... print("Hello, World.")
>>> hello
<__main__.DelayedStart object at 0x100b71130>
>>> type(hello)
<class '__main__.DelayedStart'>
>>> hello.__name__➊
'hello'
>>> hello() ➋
Wait for 1 second before starting...
Hello, World.
>>> hello.eager_call() ➌
Call without delay
Hello, World.
- ❶ 被装饰的hello函数已经变成了装饰器类DelayedStart的实例,但是因为update_wrapper的作用,这个实例仍然保留了被装饰函数的元数据。
- ❷ 此时触发的其实是装饰器类实例的__call__方法。
- ❸ 使用额外的eager_call接口调用函数。
带参数装饰器 DelayedStart
class DelayedStart:
"""在执行被装饰函数前,等待一段时间
:param func: 被装饰的函数
:param duration: 需要等待的秒数
"""
def __init__(self, func, *, duration=1): ➊
update_wrapper(self, func)
self.func = func
self.duration = duration
def __call__(self, *args, **kwargs):
print(f'Wait for {self.duration} second before starting...')
time.sleep(self.duration)
return self.func(*args, **kwargs)
def eager_call(self, *args, **kwargs): ...
def delayed_start(**kwargs):
"""装饰器:推迟某个函数的执行"""
return functools.partial(DelayedStart, **kwargs) ➋
- ❶ 把 func 参数以外的其他参数都定义为“仅限关键字参数”,从而更好地区分原始函数与装饰器的其他参数。
- ❷ 通过 partial 构建一个新的可调用对象,这个对象接收的唯一参数是待装饰函数 func,因此可以用作装饰器。
delayed_start 这个函数必不可少,实例化这个 DelayedStart 类,便于接受 func 参数。
@delayed_start(duration=2)
def hello():
print("Hello, World.")
相比传统做法,用类来实现装饰器(实例替换)的主要优势在于,你可以更方便地管理装饰器的内部状态,同时也可以更自然地为被装饰对象追加额外的方法和属性。
4. 装饰器设计技巧 #
装饰器里应该只有一层浅浅的包装代码,要把核心逻辑放在其他函数与类中。
第 9 章 面对对象编程 ⭐ #
在 Python 里,万物皆对象。
1. 私有属性 #
在 Python 里,所有的类属性和方法默认都是公开的,不过你可以通过添加双下划线前缀 __ 的方式把它们标示为私有。
class Foo:
def __init__(self):
self.__bar = 'baz'
# 上面代码中 Foo 类的 bar 就是一个私有属性,如果你尝试从外部访问它,程序就会抛出异常
>>> foo = Foo()
>>> foo.__bar
AttributeError: 'Foo' object has no attribute '__bar'
注意:Python里的私有只是一个“君子协议”。你可以使用 _{class}__{var} 这个别名来访问。
>>> foo._Foo__bar
'baz'
2. 实例所有内容都在字典内 #
一个类实例的所有成员,其实都保存在了一个名为 __dict__ 的字典属性中。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print(f"Hi, My name is {self.name}, I'm {self.age}")
查看 __dict__ :
>>> p = Person('raymond', 30)
>>> p.__dict__➊
{'name': 'raymond', 'age': 30}
>>> Person.__dict__➋
mappingproxy({'__module__': '__main__', '__init__': <function Person.__init__at 0x109611ca0>, 'say': <function Person.say at 0x109611d30>, '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None})
❶ 实例的 __dict__ 里,保存着当前实例的所有数据。
❷ 类的 __dict__ 里,保存着类的文档、方法等所有数据。
3. 内置类方法装饰器 #
1. @classmethod 装饰器(类方法) #
普通方法无法通过类来调用,但你可以用 @classmethod装饰器 定义一种特殊的方法:类方法(class method),它属于类但是无须实例化也可调用。
class Duck:
...
@classmethod
def create_random(cls): ➊
"""创建一只随机颜色的鸭子"""
color = random.choice(['yellow', 'white', 'gray'])
return cls(color=color)
❶ 普通方法接收类实例(self)作为参数,但类方法的第一个参数是类本身,通常使用名字 cls。
调用效果:
>>> d = Duck.create_random()
>>> d.quack()
Hi, I'm a white duck!
>>> d.create_random() ➊
<__main__.Duck object at 0x10f8f2f40>
2. @staticmethod 静态方法 #
如果某个方法不需要使用当前实例里的任何内容,那可以使用 @staticmethod 来定义一个静态方法。
其实和外部一个普通函数类似。但是静态方法可以被子类继承和重写。
class Cat:
def __init__(self, name):
self.name = name
def say(self):
sound = self.get_sound()
print(f'{self.name}: {sound}...')
@staticmethod
def get_sound(): ➊
repeats = random.randrange(1, 10)
return ' '.join(['Meow'] * repeats)
❶ 静态方法不接收当前实例作为第一个位置参数。
3. @preperty 属性装饰器 #
在一个类里,属性和方法有着不同的职责:属性代表状态,方法代表行为。
使用 @property装饰器,你可以把方法变成一个虚拟属性,然后像使用普通属性一样使用它:
class FilePath:
...
@property
def basename(self):
"""获取文件名"""
return self.path.rsplit(os.sep, 1)[-1]
调用效果如下:
>>> p = FilePath('/tmp/foo.py')
>>> p.basename
'foo.py'
@property 除了可以定义属性的读取逻辑外,还支持自定义写入和删除逻辑:
class FilePath:
...
@property
def basename(self):
"""获取文件名"""
return self.path.rsplit(os.sep, 1)[-1]
@basename.setter ➊
def basename(self, name): ➋
"""修改当前路径里的文件名部分"""
new_path = self.path.rsplit(os.sep, 1)[:-1] + [name]
self.path = os.sep.join(new_path)
@basename.deleter
def basename(self): ➌
raise RuntimeError('Can not delete basename!')
❶ 经过 @property 的装饰以后,basename已经从一个普通方法变成了 property 对象,因此这里可以使用 basename.setter。
❷ 定义 setter 方法,该方法会在对属性赋值时被调用。
❸ 定义 deleter 方法,该方法会在删除属性时被调用。
调用效果如下:
>>> p = FilePath('/tmp/foo.py')
>>> p.basename = 'bar.txt' # 触发 setter 方法
>>> p.path
'/tmp/bar.txt'
>>> del p.basename # 触发 deleter 方法
RuntimeError: Can not delete basename!
4. 鸭子类型 #
“鸭子类型”是 Python 语言最鲜明的特点之一,在该风格下,一般不做任何严格的类型检查。
在鸭子类型中,关注点在于对象的行为(方法/函数)能做什么;而不是关注对象所属的类型。
在使用鸭子类型的语言中,这样的一个函数可以接受一个任意类型的对象,并调用它的"走"和"叫"方法。
缺点就是:缺乏标准,不需要严格的类型校验;鸭子类型使用的前提是需要良好的文档支持,不然会让代码变得很混乱,如果没有良好的文档及说明,有可能会导致你的“鸭子”不是我的“鹅”了。

5. 抽象类 #
抽象类是一种特殊的类。
在Python中抽象类只能被继承,不能被实例化。
继承于抽象基类的子类必须给出所有抽象方法和属性的具体实现,才可以进行正常的实例化。
1. 抽象类的作用 #
在面向对象思想中,抽象基类一般用于统一接口,使得业务代码可以不随着实现得改变而改变(因为抽象基类已经确定了接口)(下两章的内容)。例如,如果把“动物”作为一个抽象类,那么它可以拥有诸如“吃”或“叫”的方法。但是,抽象类本身可以不实现方法,只需要定义框架,因为不同的子类(例如“猫”和“狗”)对方法的实现可能是不同的。既然这样,为什么不直接定义子类呢?是因为当有了抽象类后,你可以这样说“我养了一只<动物>,它这样’<动物>.吃’, 那样’<动物>.叫’“。只要传递的是”动物“的子类,那么这句话就是正确的且不需要修改的,因为”动物“这个抽象类已经把接口形式定义好了。抽象类的另一个使用方式是通过类型检查来确定某些接口是否存在,例如,“如果它是一只动物,那么它既能’吃’,又能’叫’”。
简单来说,在不同的模块中通过抽象基类来调用,可以用最精简的方式展示出代码之间的逻辑关系,让模块之间的依赖清晰简单。
抽象类的编程,让每个人可以关注当前抽象类的方法和描述,而不需要考虑过多的实现细节,这对协同开发有很大意义,也让代码可读性更高。
2. 定义抽象类 #
在 Python 中,抽象基类由标准库 abc 支持。abc 中提供了两个核心的用于抽象基类的类:ABCMeta 和 ABC,前者用于自定义抽象基类时指定为元类,而后者则提供了可以直接继承来使用的抽象基类。
# 导入抽象类需要用到的库
from abc import ABCMeta, abstractmethod
class Person(metaclass=ABCMeta):
"""使用元类(模板类)"""
pname = "这是Person抽象类" # 可以定义属性
# 定义抽象方法,抽象方法不需要方法体
# 需要在方法前加@abstractmethod装饰器
@abstractmethod
def run(self):
pass # 不需要写方法体
@classmethod # 可以定义类方法
def eat(cls):
print("在吃东西啊")
@staticmethod
def drink(): # 可以定义静态方法
print("在喝东西啊")
def sleep(self): # 可以定义普通方法
print("在睡觉啊")
继承了抽象类,必须重写抽象类中的抽象方法 @abstractmethod装饰器,否则无法实例化对象,并抛异常。
类 ABC 是 abc 模块提供的用于直接继承的抽象基类,也就是说,上面例子中所有的 metaclass=abc.ABCMeta 都可以直接替换为 abc.ABC:
import abc
class Person(abc.ABC):
"""使用元类(模板类)"""
pname = "这是Person抽象类" # 可以定义属性
@abstractmethod
def run(self):
pass # 不需要写方法体
抽象类是软件开发中一个非常重要的概念,通过定义抽象类,我们可以约定子类必需实现的方法。当我们一个类有几十上百个方法时,用抽象方法来防止子类漏掉某些方法是非常方便的做法。
6. 面向对象设计 #
-
继承提供了相当强大的代码复用机制,但同时也带来了非常紧密的耦合关系。
-
错误使用继承容易导致代码失控。
-
对事物的行为而不是事物本身建模,更容易孵化出好的面向对象设计。
-
在创建继承关系时应当谨慎。用组合来替代继承有时是更好的做法。
7. 有序组织你的类方法 #
在组织类方法时,我们应该关注使用者的诉求,把他们最想知道的内容放在前面,把他们不那么关心的内容放在后面。
-
作为惯例,
__init__实例化方法应该总是放在类的最前面,__new__方法同理。 -
公有方法应该放在类的前面,因为它们是其他模块调用类的入口,是类的门面,也是所有人最关心的内容。
-
以
_开头的私有方法,大部分是类自身的实现细节,应该放在靠后的位置。 -
以
__开头的魔法方法比较特殊,通常按照方法的重要程度来决定它们的位置。比如一个迭代器类的__iter__方法应该放在非常靠前的位置,因为它是构成类接口的重要方法。 -
最后一点,当你从上往下阅读类时,所有方法的抽象级别应该是不断降低的,就好像阅读一篇新闻一样,第一段是新闻的概要,之后才会描述细节。
第 10 章 面向对象的设计原则(上) #
SOLID 原则的雏形来自 Robert C. Martin(Bob大叔)于2000年发表的一篇文章。
SOLID 单词里的5个字母,分别代表5条设计原则。
- S:single responsibility principle(单一职责原则,SRP)。(类的指责有关)
- O:open-closed principle(开放–关闭原则,OCP)。(类的修改与扩展)
- L:Liskov substitution principle(里式替换原则,LSP)。(和继承有关)
- I:interface segregation principle(接口隔离原则,ISP)。(和编写接口中更精确的抽象)
- D:dependency inversion principle(依赖倒置原则,DIP)。(和编写接口抽象有关)
1. 类型注释基础 #
下面是添加了类型注解后的代码:
from typing import List
class Duck:
def __init__(self, color: str): ➊
self.color = color
def quack(self) -> None: ➋
print(f"Hi, I'm a {self.color} duck!")
def create_random_ducks(number: int) -> List[Duck]: ➌
ducks: List[Duck] = [] ➍
for _ in number:
color = random.choice(['yellow', 'white', 'gray']) ➎
ducks.append(Duck(color=color))
return ducks
❶ 给函数参数加上类型注解。
❷ 通过->给返回值加上类型注解。
❸ 你可以用typing模块的特殊对象List来标注列表成员的具体类型,注意,这里用的是[]符号,而不是()。
❹ 声明变量时,也可以为其加上类型注解。
❺ 类型注解是可选的,非常自由,比如这里的 color 变量就没加类型注解。
2. SRP: 单一职责原则 #
SRP认为:一个类应该仅有一个被修改的理由。换句话说,每个类都应该只承担一种职责。
单个类承担的职责越多,就意味着这个类越复杂,越难维护。
怎么修改脚本才能让它符合 SRP 呢?
办法有很多,其中最传统的就是把大类拆分为小类。
函数同样可以做到“单一职责。将某个职责拆分为新函数是一个具有 Python 特色的解决方案。它虽然没有那么“面向对象”,却非常实用,甚至在许多场景下比编写类更简单、更高效。
3. OCP:开放-关闭原则 #
该原则认为:类应该对扩展开放,对修改封闭。换句话说,你可以在不修改某个类的前提下,扩展它的行为。(本身不变,但是易于扩展)
1. 通过继承改造代码 #
继承提供了强大的代码复用能力。继承允许我们用一种新增子类而不是修改原有类的方式来扩展程序的行为,这恰好符合OCP。
而要做到有效地扩展,关键点在于先找到父类中不稳定、会变动的内容。只有将这部分变化封装成方法(或属性),子类才能通过继承重写这部分行为。
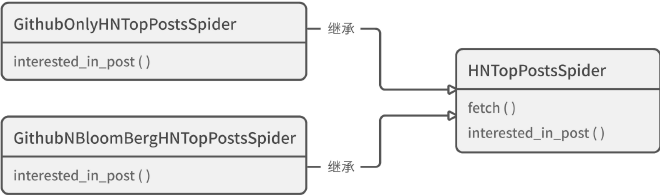
2. 使用组合与依赖注入 #
除了继承外,我们还可以采用另一种思路:组合(composition)。更具体地说,使用基于组合思想的依赖注入(dependency injection)技术。
依赖注入允许我们在创建对象时,将业务逻辑中易变的部分(常被称为“算法”)通过初始化参数注入对象里,最终利用多态特性达到“不改代码来扩展类”的效果。
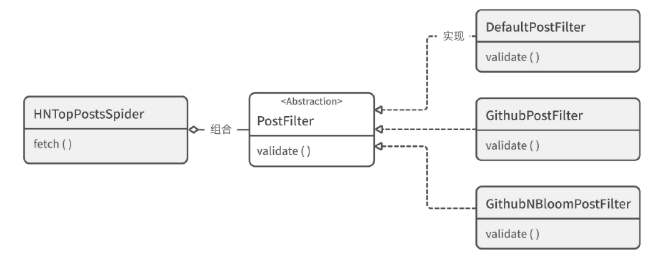
所以我必须编写一个抽象类,以此满足类型注解的需求。
3. 使用数据驱动 #
它的核心思想是:将经常变动的部分以数据的方式抽离出来,当需求变化时,只改动数据,代码逻辑可以保持不动。
依赖注入抽离的通常是类,而数据驱动抽离的是纯粹的数据。
- 优点:使用数据驱动的代码明显更简洁,因为它不需要定义任何额外的类。
- 缺点:它的可定制性不如其他两种方式。
影响每种方案可定制性的根本原因在于,各方案所处的抽象级别不一样。
第 11 章 面向对象的设计原则(下) #
1. LSP:里式替换原则 #
LSP认为,所有子类(派生类)对象应该可以任意替代父类(基类)对象使用,且不会破坏程序原本的功能。
1. 违反 LSP 的几种常见方式 #
- 子类抛出了父类所不认识的异常类型;
- 子类的方法返回值类型与父类不同,并且该类型不是父类返回值类型的子类;
- 子类的方法参数与父类不同,并且参数要求没有变得更宽松(可选参数)、同名参数没有更抽象。
2. 调整方式 #
- 有时你得在父类中引入新的异常类型;
- 有时你得尝试用组合替代继承;
- 有时你需要调整子类的方法参数。
2. DIP:依赖倒置原则 #
DIP是一条与依赖关系相关的原则。它认为:高层模块不应该依赖低层模块,二者都应该依赖抽象。 (这一章会涉及之前讲的抽象类)
DIP 里的“抽象”特指编程语言里的一类特殊对象,这类对象只声明一些公开的 API,并不提供任何具体实现。 (和抽象类中的抽象函数 @abstractmethod 理念一致)
from abc import ABC, abstractmethod
class Drawable(ABC):
@abstractmethod
def draw(self):
...
设计抽象,其主要任务是确定这个抽象的职责与边界。
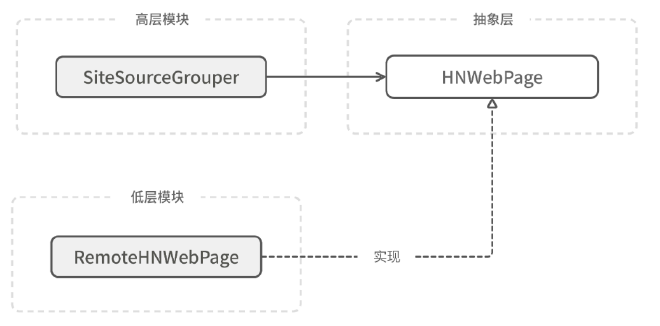
当你习惯了DIP以后,会发现抽象不仅仅是一种编程手法,更是一种思考问题的特殊方式。只要愿意动脑子,你可以在代码的任何角落里都硬挤出一层额外抽象。
事实是,抽象的好处显而易见:它解耦了模块间的依赖关系,让代码变得更灵活。但抽象同时也带来了额外的编码与理解成本。
3. ISP:接口隔离原则 #
ISP对如何使用接口提出了要求:客户(client)不应该依赖任何它不使用的方法。
ISP里的“客户”不是使用软件的客户,而是接口的使用方——客户模块,也就是依赖接口的高层模块。
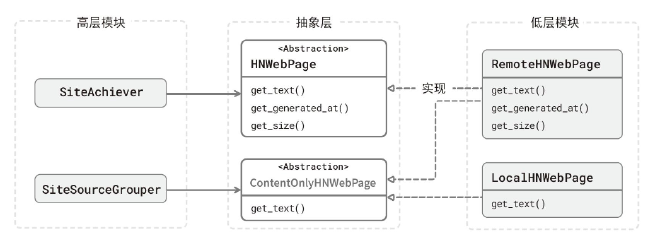
1. 违反 ISP #
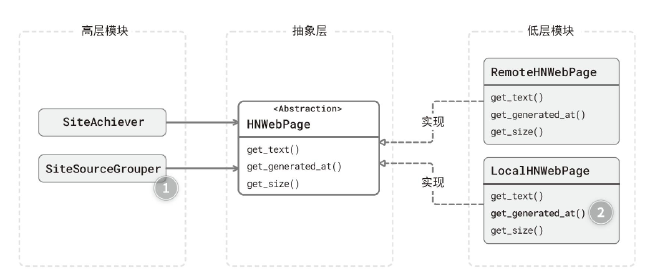
- 问题1:SiteSourceGrouper 类依赖了 HNWebPage,但是并不使用后者的 get_size()、get_generated_at()方法。
- 问题2:LocalHNWebPage 类为了实现 HNWebPage 抽象,需要“退化” get_generated_at() 方法。
2. 拆分接口 #
让客户(调用方)来驱动协议设计。在现在的程序里,HNWebPage接口共有两个客户。
HNWebPage接口共有两个客户。
- SiteSourceGrouper:按域名来源统计,依赖 get_text()。
- SiteAchiever:页面归档程序,依赖 get_text()、get_size() 和 get_generated_at()。
第 12 章 数据模型与描述符 #
P324 – P355
第 13 章 开发大型项目 #
本章主要介绍常用的代码格式化工具、常用的测试工具和实用的单元测试技巧。
1. 格式化检查工具 #
1. flake8 #
利用 flake8,你可以轻松检查代码是否遵循了 PEP 8 规范。
flake8的PEP 8检查功能,并非由flake8自己实现,而是主要由集成在flake8里的另一个Linter工具pycodestyle提供。
2. isort #
PEP 8认为,一个源码文件内的所有import语句,都应该依照以下规则分为三组:
- 导入Python标准库包的import语句;
- 导入相关联的第三方包的import语句;
- 与当前应用(或当前库)相关的import语句。
借助 isort,我们不用手动进行任何分组,它会帮我们自动做好这些事。
3. black #
black 是一个更为严格的格式化工具。
black用起来很简单,只要执行black {filename}命令即可。
4. mypy #
为了在程序执行前就找出由类型导致的潜在bug,提升代码正确性,人们为Python开发了不少静态类型检查工具,其中mypy最为流行。
在大型项目中,类型注解与mypy的组合能大大提升项目代码的可读性与正确性。给代码写上类型注解后,函数参数与变量的类型会变得更明确,人们在阅读代码时更不容易感到困惑。再配合mypy做静态检查,可以轻松找出藏在代码里的许多类型问题。
1. 单元测试 #
1. unittest #
unittest 是标准库里的单元测试模块,使用方便,无须额外安装。
import unittest
class TestStringUpper(unittest.TestCase):
def test_normal(self):
self.assertEqual('foo'.upper(), 'FOO')
if __name__== '__main__':
unittest.main()
用 unittest 编写测试用例的第一步,是创建一个继承 unittest.TestCase 的子类,然后编写许多以 test 开头的测试方法。
在方法内部,通过调用一些以 assert 开头的方法来进行测试断言,如下所示。
- self.assertEqual(x, y):断言x和y必须相等。
- self.assertTrue(x):断言x必须为布尔真。
- self.assertGreaterEqual(x, y):断言x必须大于等于y。
在 unittest 包内,这样的 assert{X} 方法超过30个。
2. pytest #
pytest是一个开源的第三方单元测试框架。
def string_upper(s: str) -> str:
"""将某个字符串里的所有英文字母由小写转换为大写"""
chars = []
for ch in s:
# 32 是小写字母与大写字母在ASCII 码表中的距离
chars.append(chr(ord(ch) - 32))
return ''.join(chars)
为了测试函数的功能,我用pytest写了一份单元测试:
文件:test_string_utils.py
from string_utils import string_upper
def test_string_upper():
assert string_upper('foo') == 'FOO'
用 pytest 执行上面的测试文件,会输出以下结果:
$ pytest test_string_utils.py
===================== test session starts =====================
platform darwin -- Python 3.8.1, pytest-6.2.2
rootdir: /python_craftman/
collected 1 item
test_string_utils.py . [100%]
====================== 1 passed in 0.01s ======================
用 parametrize 编写参数化测试
在单元测试领域,有一种常用的编写测试代码的技术:表驱动测试(table-driven testing)。
import pytest
from string_utils import string_upper
@pytest.mark.parametrize(
's,expected', ➊
[
('foo', 'FOO'), ➋
('', ''),
('foo BAR', 'FOO BAR'),
],
)
def test_string_upper(s, expected): ➌
assert string_upper(s) == expected ➍
- ❶ 用逗号分隔的参数名列表,也可以理解为数据表每一列字段的名称;
- ❷ 数据表的每行数据通过元组定义,元组成员与参数名一一对应;
- ❸ 在测试函数的参数部分,按parametrize定义的字段名,增加对应参数;
- ❹ 在测试函数内部,用参数替换静态测试数据。
pytest 的功能非常强大,本节只对它做了最基本的介绍。如果你想在项目里使用pytest,可以阅读它的官方文档,里面的内容非常详细。
写在最后 #
除了本章提到的这些内容以外,我还建议你继续学习一些敏捷编程、领域驱动设计、整洁架构方面的内容。从我的个人经历来看,这些知识对于大型项目开发有很好的启发作用。
无论如何,永远不要停止学习。